Framework Overview
The GDDAI Architecture
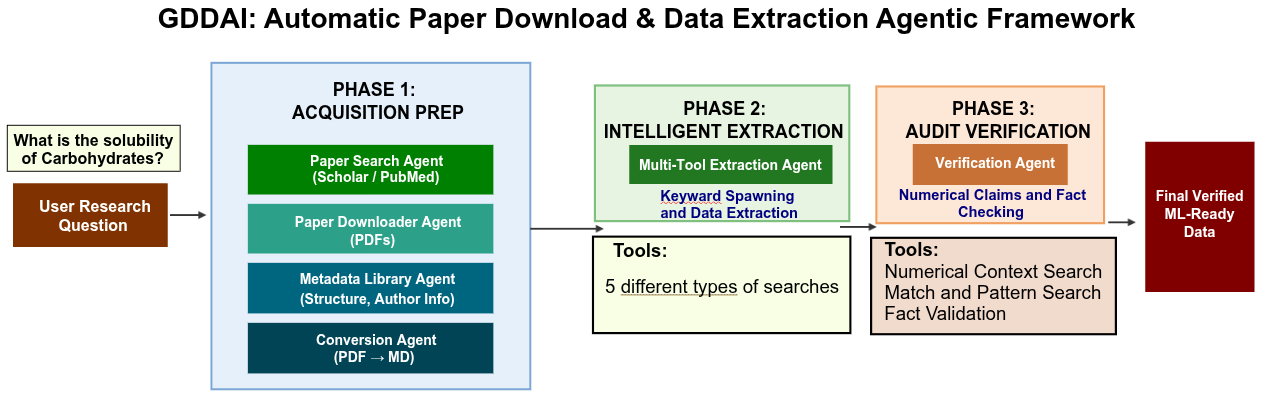
A three-phase agentic pipeline that turns a plain-language research question into a curated, numerically verified tabular dataset.
GDD — GlycoDataDigest
GDDAI automates scientific literature discovery, intelligent PDF extraction, and fact-verified ML-ready dataset generation — end to end.
Framework Overview
A three-phase agentic pipeline that turns a plain-language research question into a curated, numerically verified tabular dataset.
Three-Phase Pipeline
Each phase is handled by a specialised agent with dedicated tools.
Searches Google Scholar and PubMed using the user's research keyword, ranks results by semantic similarity, and downloads full PDF articles.
Bulk-downloads PDFs, enriches each with author metadata and molecular structure info, then converts every PDF to clean Markdown for downstream agents.
An LLM agent equipped with 5 different search tools spawns keyword-driven extraction passes, pulling numerical values into structured tabular rows.
A dedicated auditor agent cross-checks every extracted value against the source document — validating numerical accuracy, units, and citation details before export.
Core Capabilities
Four tightly-integrated capabilities that cover the full research-to-data lifecycle.
Enter any research keyword and GDDAI automatically searches Google Scholar and PubMed, identifies relevant papers, and downloads their PDF full-texts — no manual browsing required.
Retrieved papers are ranked by cosine similarity against the search query embedding, ensuring the most relevant literature reaches the extraction stage first and irrelevant documents are deprioritised automatically.
An LLM agent with tool-calling capabilities deploys five specialised search strategies over the converted Markdown text — keyword spawning, table parsing, unit normalisation — and outputs ML-ready tabular data without manual annotation.
A separate Verification Agent independently audits every extracted data point — checking numerical context, pattern matching against source sentences, validating units, and confirming full citation details before the dataset is finalised.
Output Dataset
A curated, numerically-verified dataset of physicochemical properties extracted from peer-reviewed glycan literature.
Automatically assembled from primary literature and verified at the source-sentence level. Structured for direct use in regression models, property-prediction benchmarks, and QSPR / QSAR workflows.
Sample Schema
| compound | property | value | unit | temperature | source_doi | verified |
|---|---|---|---|---|---|---|
| Sucrose | solubility | 2000 | g/L | 25 °C | 10.1002/... | ✓ |
| Trehalose | glass_transition_temp | 115 | °C | — | 10.1021/... | ✓ |
| Maltose | viscosity | 1.84 | mPa·s | 20 °C | 10.1039/... | ✓ |
Developer Access
All GlycoDataDigest datasets are accessible via a public REST API built with Django REST Framework. Query any property endpoint directly into your Python, R, or workflow scripts.
https://glycodata.org/api/gdd/| Resource | Endpoint | Method |
|---|---|---|
| 💧 Solubilities | /api/gdd/solubilities/ | GET |
| 🌊 Viscosities | /api/gdd/viscosities/ | GET |
| ⚡ Activation Energies | /api/gdd/activation-energies/ | GET |
| 🔀 Diffusion Constants (T1) | /api/gdd/diffusion-constants-table1/ | GET |
| 🔀 Diffusion Constants (T2) | /api/gdd/diffusion-constant-table2/ | GET |
| 💦 Hygroscopicity | /api/gdd/hygroscopicity/ | GET |
| 🔄 Optical Rotations | /api/gdd/optical-rotations/ | GET |
| 🌡️ Glass Transition Temps. | /api/gdd/glass-transition-temperatures/ | GET |
| 🌈 IR Spectra | /api/gdd/ir-spectra/ | GET |
Usage Example